
AgriVIVO prototype: architecture
The AgriVIVO prototype will be published in January 2013.
The purpose of the AgriVIVO prototype is to demonstrate the functionalities of the AgriVIVO store and search portal.
The product of this first stage will be used primarily by the members of the participating communities and also by the general audience identified in the business case, but mostly as a demonstrative product.
The prototype will import, store and allow to browse data on people, organizations and events in the field of agriculture.
The prototype will consist of:
-
A prototype central AgriVIVO database (RDF store with SPARQL engine and Solr index) storing data about (and relationships between) people, organizations and events (indexed by field of expertise / areas of activity and by country). The initial data will be imported from a few existing platforms that manage data about people, organizations and events in a structured way (like e-agriculture, EGFAR, AgriFeeds, AIMS, IAALD, the RING).
The central store will be built on top of an application (VIVO) that allows to import structured data and transform them into RDF triples according to the VIVO model (extended with a small additional AgriVIVO RDF vocabulary).
The key difference between this AgriVIVO store and standard VIVO stores is that data are imported from several different sources and there is no manual curation, at least in the first phase. This requires the implementation of new customized importers.
The customization for agriculture also requires an extension of the VIVO ontology.The initial data will be imported from a few existing platforms that manage data about people, organizations and/or events in agriculture in a structured way: the minimum initial set of sources will consist of: the e-agriculture platform, the EGFAR contact database, AgriFeeds, the AIMS community, the IAALD community, the CIARD and RING databases, for an estimated total of around 12,000 experts, 400 Institutions and 2,000 events.
-
A prototype Global AgriVIVO search portal that allows users to search / browse the database by topic, by country, by organization type.
The prototype will also expose at least one widget for including AgriVIVO functionalities in other websites...
The reason for setting up AgriVIVO as two services is that the VIVO software and the Drupal CMS have different specializations:
-
VIVO specializes in storing and managing ontologies and data described by the ontologies; it also allows for importing daa and for manually curating them.
The browse and search functionalities of VIVO are not very user-friendly and modifying the look and feel and the way search results are rendered is not very easy.
Besides, it cannot rely on a big community of developers for adding typical front-end functionalities (like social media, feeds, calendars etc.) that may be needed by the AgriVIVO front-end in the future.
- Drupal specializes in providing several customizable ways of browsing and displaying data; it can harvest structured data; it allows to easily modify the look and feel of a website; it allows to add advanced front-end functionalities thanks to hundreds of available modules.
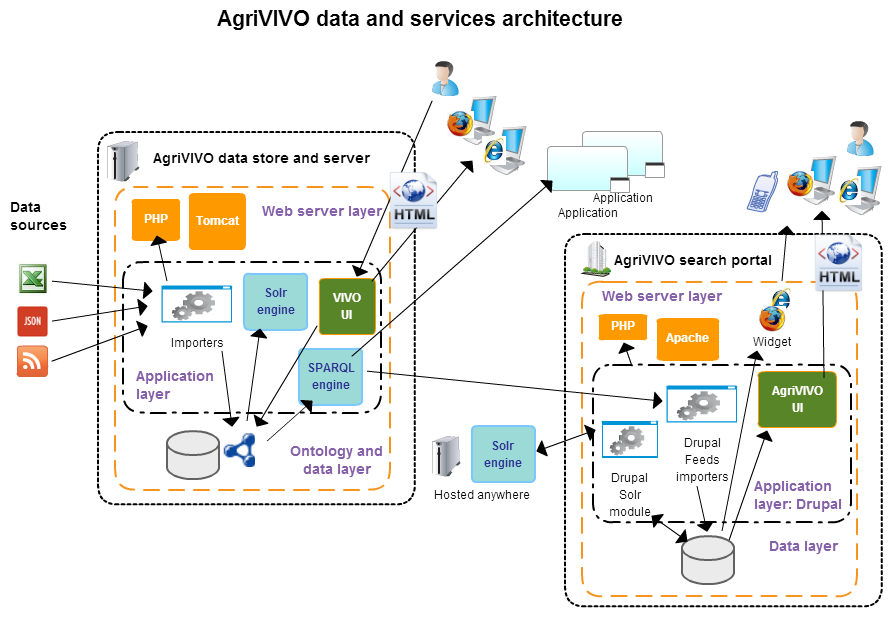
The service will be deployed in the following way (see fig. 1):
A customized VIVO instance that will manage the AgriVIVO store:
- This VIVO instance will expose a Solr index and a SPARQL engine on the data; it will have to be accessible via http publicly; it will have to be hosted on a server with sufficient resources and bandwidth to cope with queries from other systems;
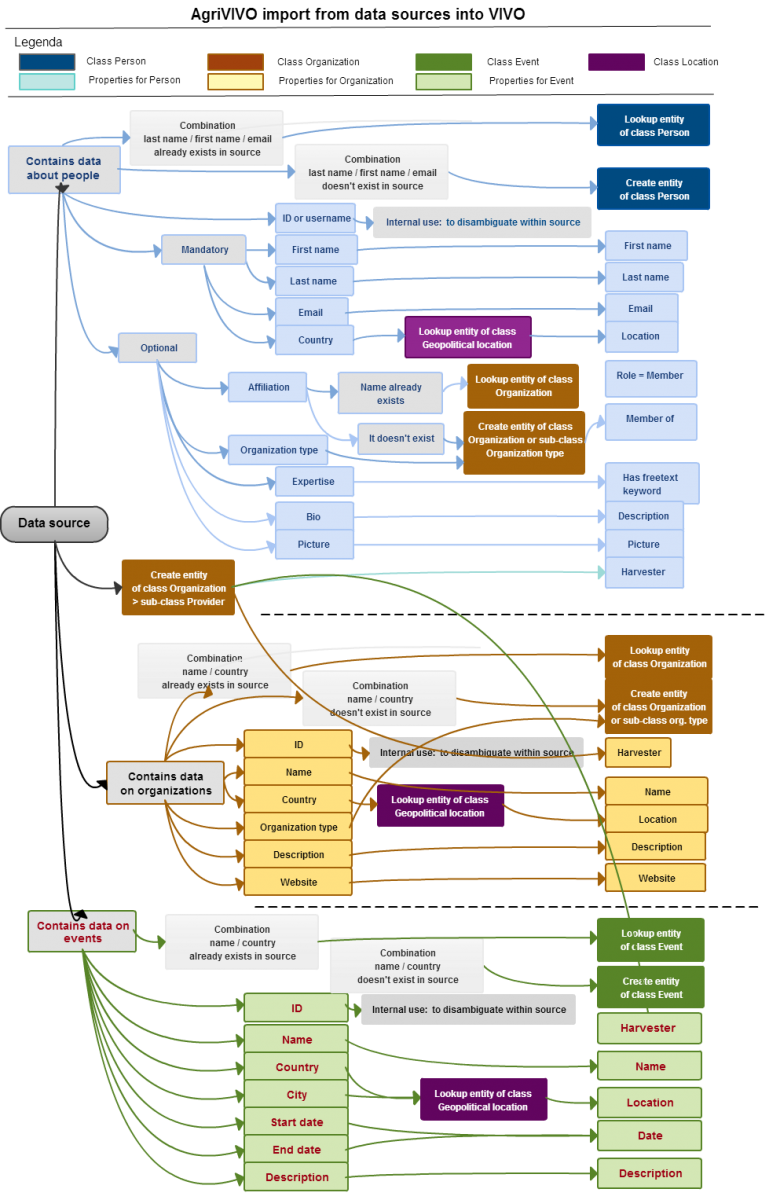
- This VIVO instance will have customized VIVO importers to map the data from AgriVIVO data sources to the AgriVIVO RDF model (see fig. 2) and import them: the importers will have some initial form of disambiguation algorithms; the importers will support at least two different formats (e.g. CSV and Json), relying on a small set of agreed mandatory data;
- This VIVO instance will integrate the AgriVIVO ontology, which will add sub-classes and properties if necessary to better cover the agricultural domain.
A Drupal instance for the end-user search portal:
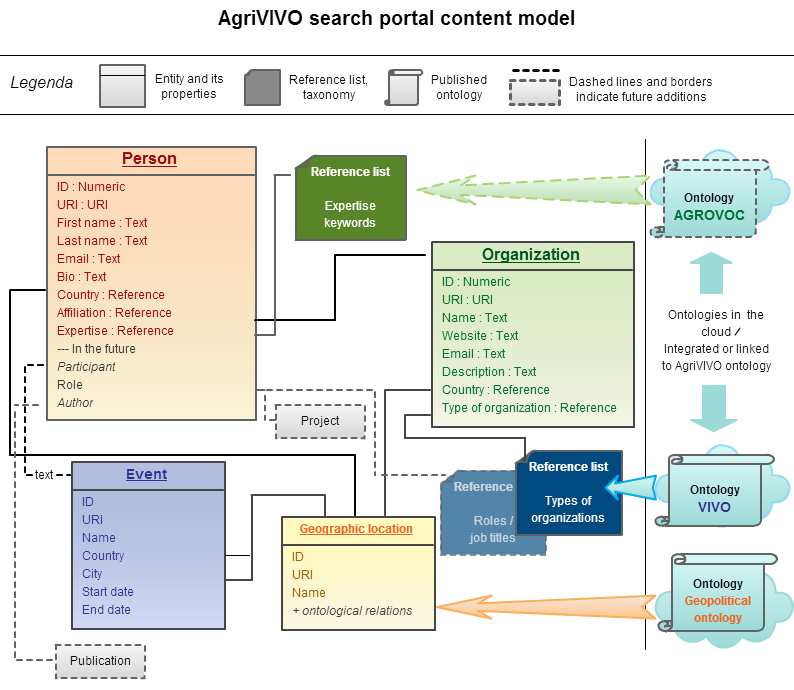
- The Drupal portal will have a content model as described in fig. 3;
- The Drupal portal will harvest data from the AgriVIVO store via the VIVO SPARQL endpoint; it will use custom plugins for the the Drupal Feeds module to do this;
- The Drupal portal will allow for searches on the three main entities (people, organizations, events), in the form of both a free-text search and “faceted” searches by country (all entities), expertise (people), type of organization (organization), date (events); these searches will be based on a customized Solr index set up through the Drupal ApacheSolr module;
- The Drupal portal will use as much as possible standard Drupal solutions (modules, plugins) and any special code or configurations will be wrapped into Drupal features that can be easily deployed in a Drupal site;
- The Drupal portal will be published at the main URL www.agrivivo.net and will also host the RDF version of the AgriVIVO ontology under the path http://www.agrivivo.net/ontology/agrivivo.
from the project documentation

